스테이블 디퓨전을 접한 지 한 일주일 정도 되는 것 같다. 이때까지 배운 걸 좀 정리하려고 한다. 스테이블 디퓨전이란 AI 이미지 생성기로써, 텍스트나 이미지를 기반으로 여러 AI모델을 통해 새로운 이미지를 생성한다. 아래 영상과 함께 본다면 보다 이해하기 쉬울 것이다.
< 스테이블디퓨전 연구소 오픈 채팅방 >
(같이 공부하고 싶다면 아래 링크 클릭!)
https://open.kakao.com/o/glPd6M8e
1. 스테이블 디퓨전 개요
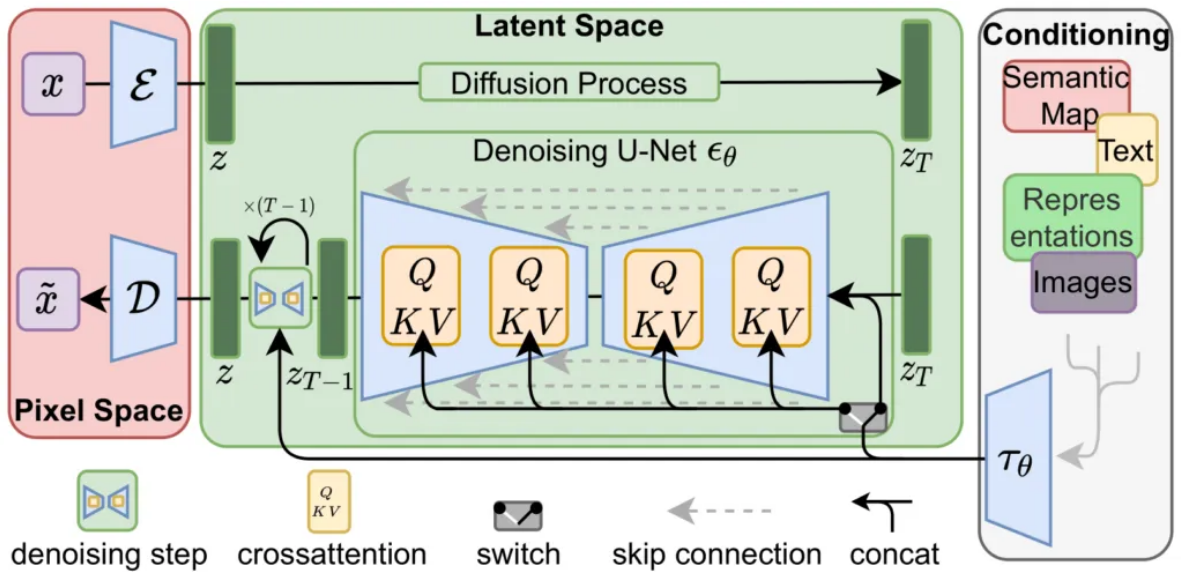
| Stable dIffusion은 크게 보면 CLIP, UNet, VAE(Variational Auto Encoder, 자기부호화기)이라는 세 가지 인공신경망으로 이루어져 있다. 유저가 텍스트를 입력하면 텍스트 인코더(CLIP)가 유저의 텍스트를 토큰(Token)이라는 UNet이 알아들을 수 있는 언어로 변환하고, UNet은 토큰을 기반으로 무작위로 생성된 노이즈를 디노이징하는 방식이다. 디노이징을 반복하다 보면 제대로 된 이미지가 생성되며, 이 이미지를 픽셀로 변환하는 것이 VAE의 역할이다. 해상도가 높아질수록 리소스를 기하급수적으로 사용하게 되는 종전의 확산 확률 이미지 생성 모델과 달리, 앞뒤에 오토인코더를 도입하여 이미지 전체가 아닌 훨씬 작은 차원의 잠재공간(latent space)에서 노이즈를 삽입/제거하므로, 비교적 큰 해상도의 이미지를 생성하는데도 리소스 사용량을 대폭 줄여 일반 가정의 그래픽카드 정도로도 이용이 가능해진 것이 특징이다. - 출처 : 나무위키 |
나무위키는 저러한데 솔직히 무슨 말인지 모르겠다. 원리는 집어치우고, 활용만 잘하자. 일단 스테이블 디퓨전은 컴퓨터와 웹으로 돌릴 수가 있다. 컴퓨터에서는 고성능 그래픽 카드 등 여러 장비가 필요하기 때문에 코랩을 사용하겠다. 코랩은 웹 기반 코드에디터로 클라우드 서버를 통해 스테이블 디퓨전을 사용하겠다.
아래 링크를 통해 구글 드라이브에 코랩을 설치할 수 있다.
https://github.com/AUTOMATIC1111/stable-diffusion-webui
GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
github.com
< 최신 스테이블디퓨전 입문 영상(2023. 6. 9.)을 참고하세요! >
2. 스테이블 디퓨전 설치
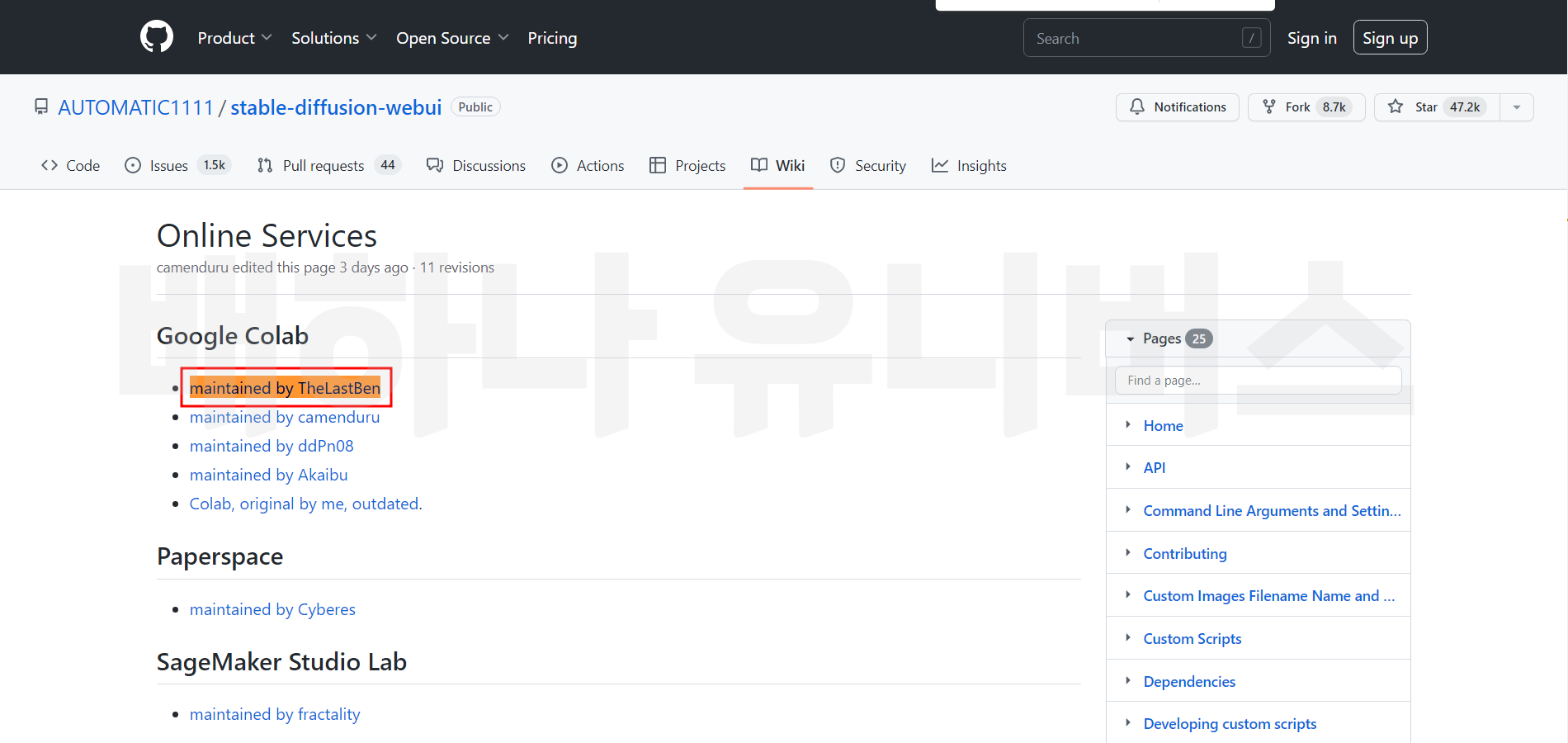
들어가면 이런 화면이 나온다. 깃허브 사이트가 나온다. 깃허브는 깃(Git) 저장소로, 일종의 코드 커뮤니티라고 보면 된다. 아래 화면에서 스크롤을 'List of Online Services' 링크로 들어가면 된다. 못 찾겠으면 Ctrl + F를 눌러 검색하면 된다. 그리고 다음 정면에 있는 'maintained by TheLastBen' 링크를 클릭하면 구글 드라이브에 코랩이 설치가 된다.
3. 스테이블 디퓨전 실행
링크를 누르면 아래 화면처럼 나온다. 아래 화면은 실행 중인 장면으로 붉은색 칸에 있는 실행 버튼을 전부 눌러야 된다. 스크롤을 끝까지 내려서 눌러야 한다. 그러면 running on public이 나온다 그 옆 링크를 클릭하자.
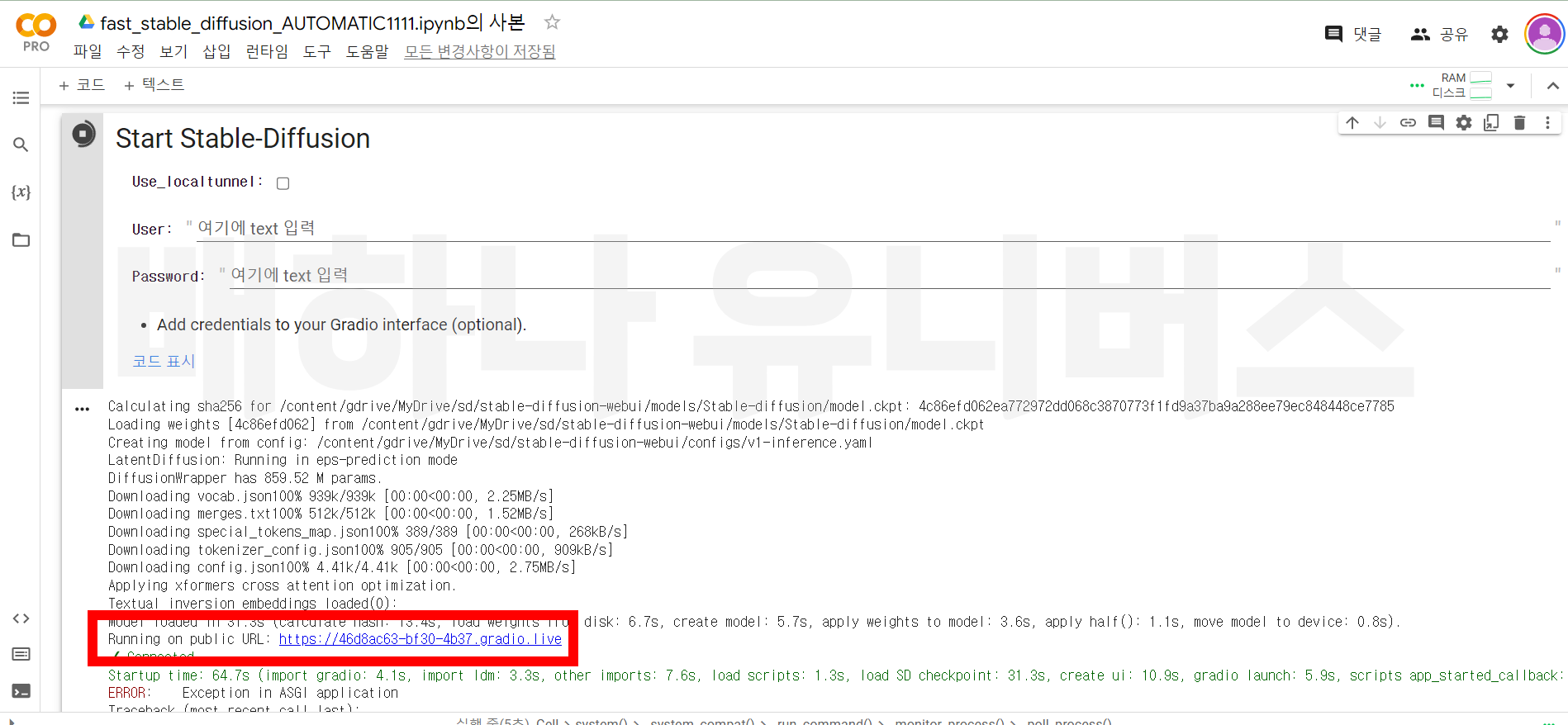
4. 스테이블 디퓨전 모델 설정
그러면 아래 화면이 나온다. 이 상태에서 실행해도 되지만 모델이 없기 때문에 별로 이쁘지 않다. 모델을 설치를 해줘야 한다. 아래 4개의 모델을 다운로드하자. 여러 모델이 있지만 주로 아래 모델을 쓰고 있으며, 다른 모델을 쓰고 싶다면 civitai와 huggingface에서 원하는 모델을 구할 수 있다. 체크포인트와 임베딩은 아래 링크를 클릭하면 바로 다운로드할 수 있고, 로라와 배는 맨 아래 파일을 다운로드하면 된다.
< 스테이블 디퓨전 모델 >
- CheckPoint: https://civitai.com/api/download/models/11745
-Embedding :https://civitai.com/api/download/models/5637
- Lora : https://huggingface.co/datasets/KrakExilios/koreandoll/tree/main
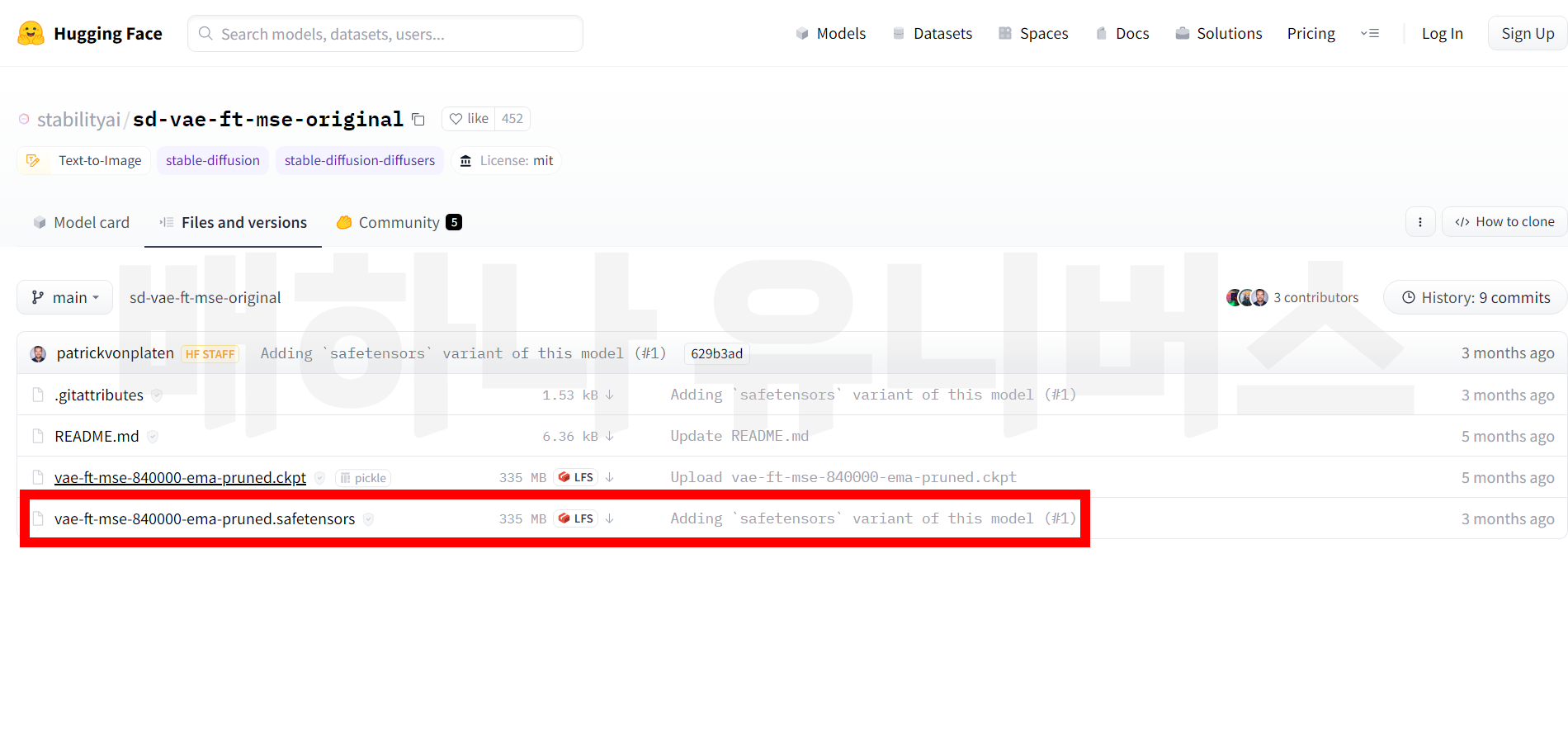
- VAE : https://huggingface.co/stabilityai/sd-vae-ft-mse-original/tree/main
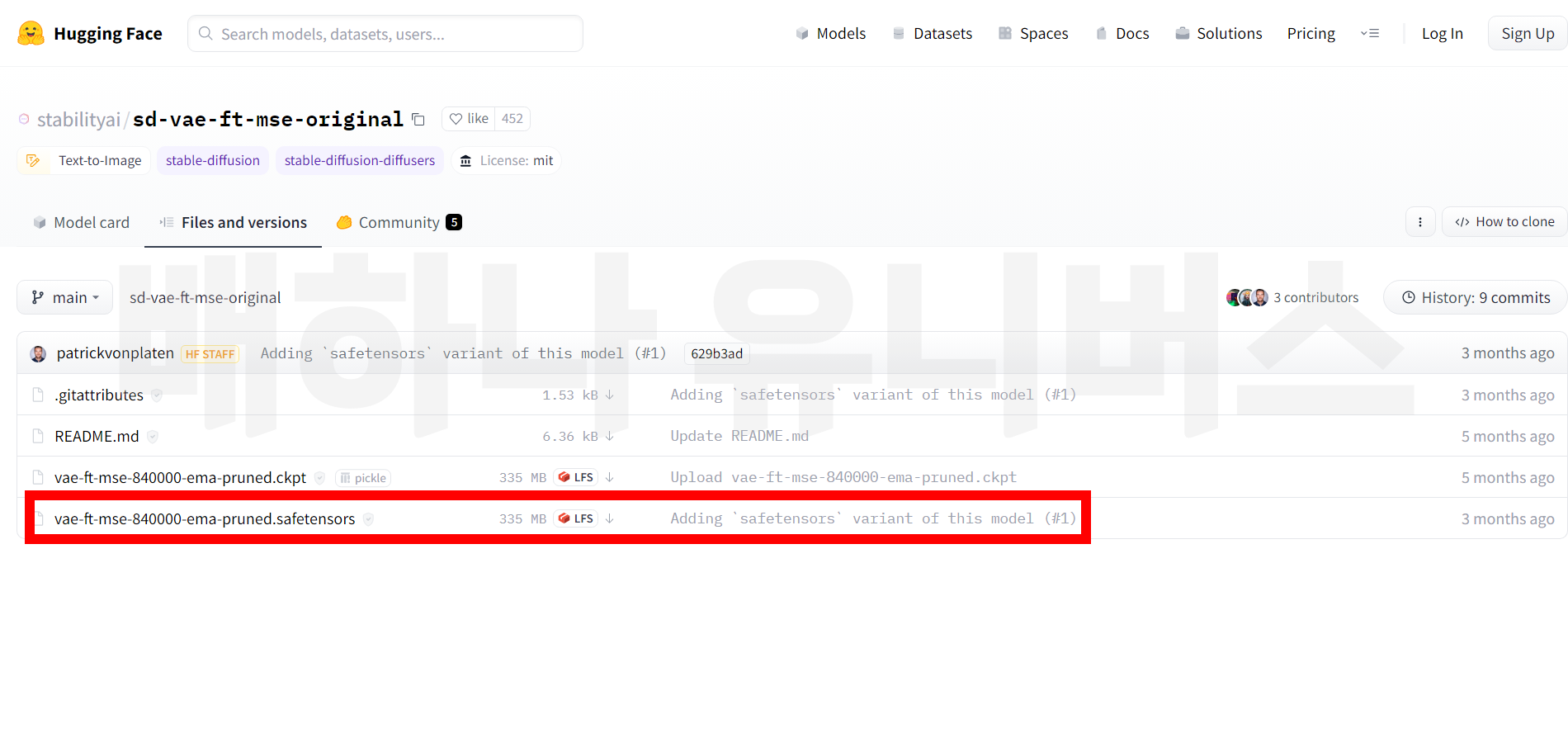
< 모델 참고 사이트 >
- civitai : https://civitai.com/ * 선정적인 장면이 나올 수 있다. 주의!
Civitai | Stable Diffusion models, embeddings, hypernetworks and more
Civitai is a platform for Stable Diffusion AI Art models. We have a collection of over 1,700 models from 250+ creators. We also have a collection of 1200 reviews from the community along with 12,000+ images with prompts to get you started.
civitai.com
- huggingface : https://huggingface.co/
Hugging Face – The AI community building the future.
The AI community building the future. Build, train and deploy state of the art models powered by the reference open source in machine learning.
huggingface.co
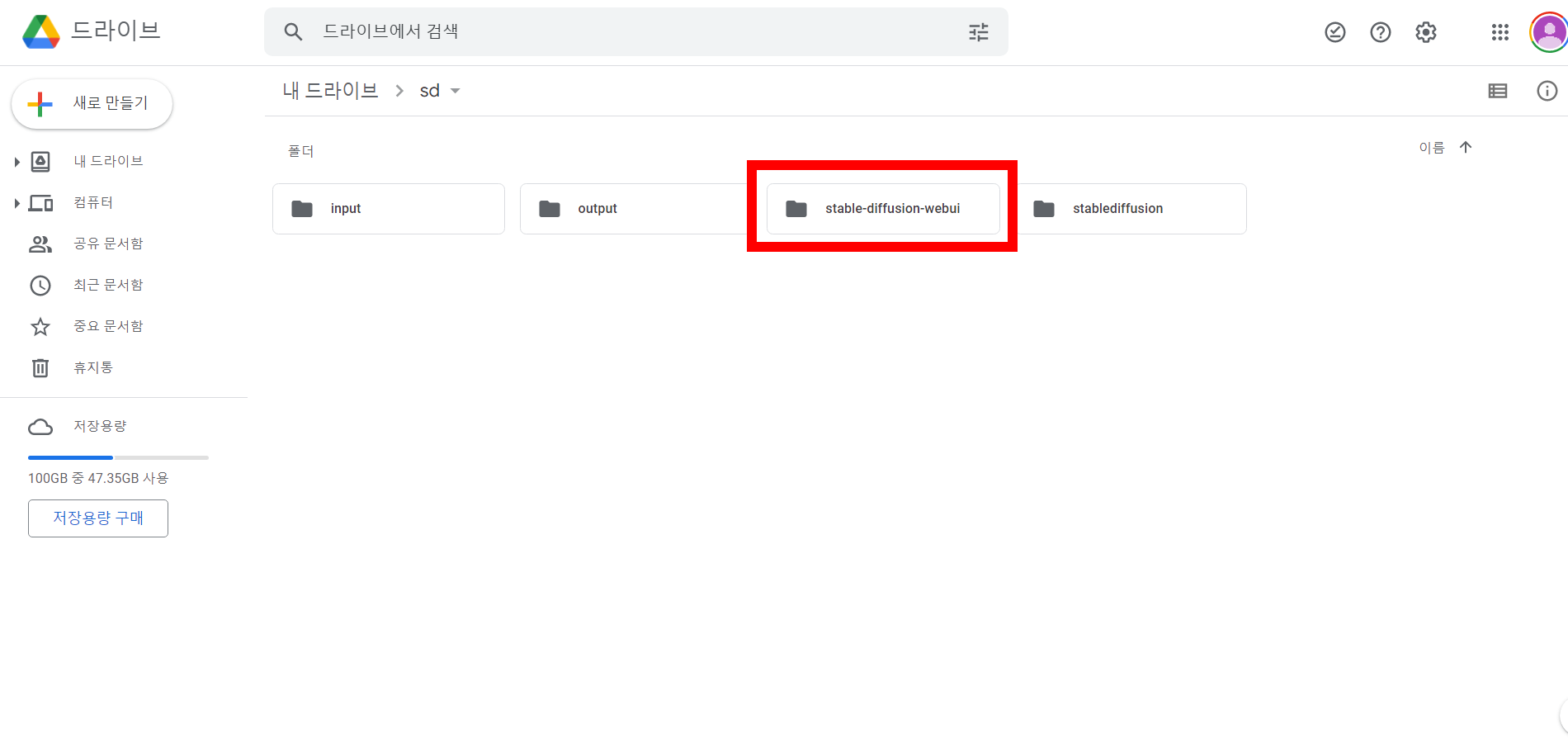
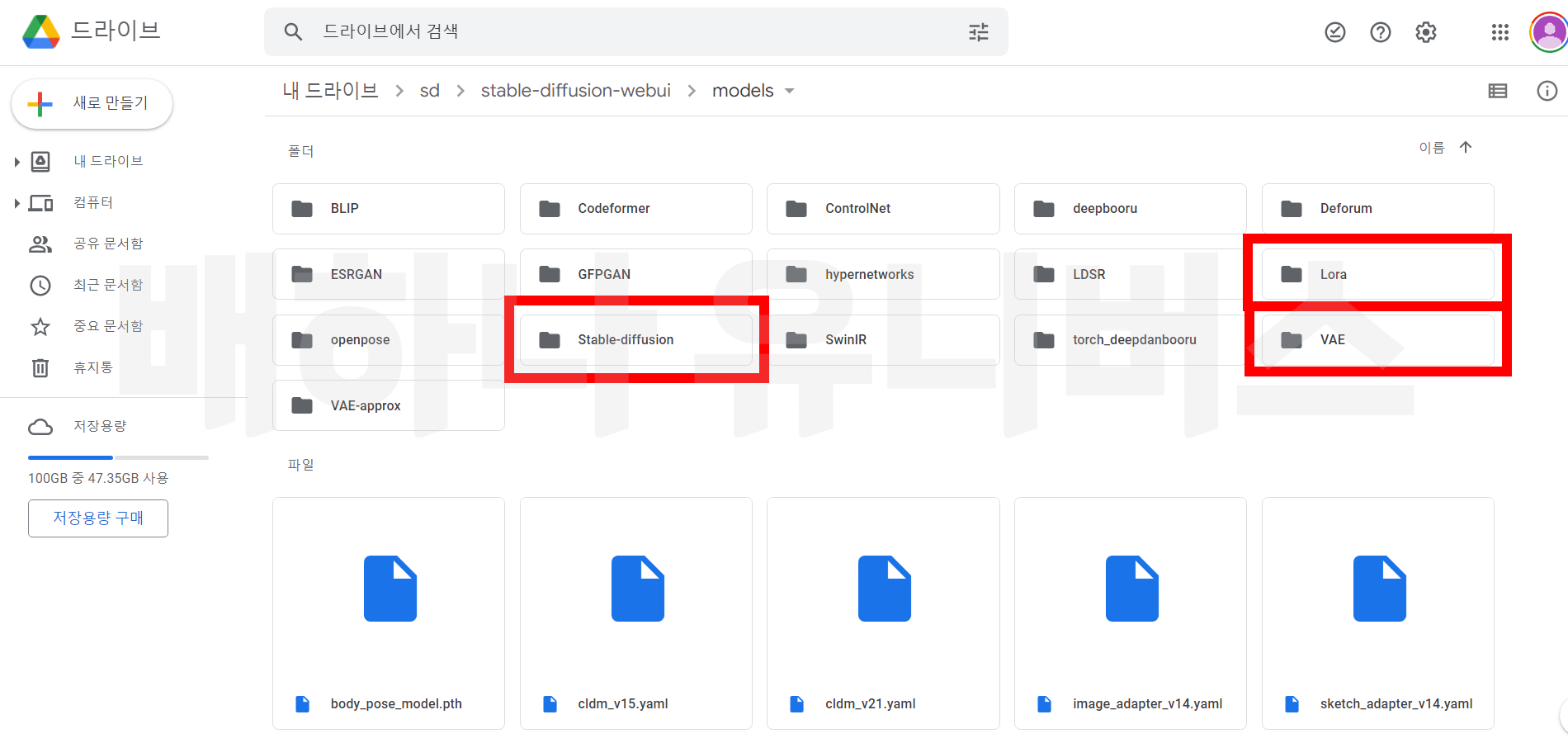
각 모델에 따른 이름은 아래 참고와 같다. 모델 파일을 다 받았으면, 아래 구글드라이브에 sd 폴더에 가면 'stable-diffusion-webui' 폴더가 있다. 모델을 아래 경로에 맞춰서 붙여 넣기 한다. 모델 설명은 아래를 참고하고, 이외에도 다양한 범주의 모델이 있다.
< 모델 설명 >
모델에 대해서 간단히 설명하자면, 체크포인트는 베이스 모델이다. 예를 들어 실사 모델로 만들 건지. 카툰 모델로 만들 건지. 큰 모델 범주라고 생각하면 된다. 다음은 로라, 배, 임베딩 순서대로 중요하다고 생각한다. 로라는 큰 범주에서 작은 범주로 좁히는 모델이다. 우리가 앞으로 할 모델을 체크포인트는 실사 모델이고, 로라는 한국 여성 모델로 한다고 생각하면 된다. 배는 보정 모델이고, 임베딩은 모델은 두고, 프롬프트를 조정한다. 예를 들어 우리는 네거티브 프롬프트 임베딩 파일로 선정적이거나 기괴한 이미지 생성을 방지하고 있다.
(요약) CheckPoint : 베이스 모델, Lora : 디테일 모델, Vae : 보정, Embedding : 프롬프트 설정 * 개인적인 생각임
< 참고 및 경로 >
-CheckPoint : chilloutmix_NiPrunedFp32Fix
* 경로 : sd-'stable-diffusion-webui' - models - stable-diffusion
-Lora : koreanDollLikeness_v15
* 경로 : sd-'stable-diffusion-webui' - models - Lora
- Vae : vae-ft-mse-840000-ema-pruned
*경로 : sd-'stable-diffusion-webui' - models - VAE
-Embedding : ng_deepnegative_v1_75t
* 경로 :sd-'stable-diffusion-webui' - embeddings

5. 스테이브 디퓨전 실행창 설명
설정을 했으면 다시 스테이블 디퓨전 화면으로 돌아가자. 일단 좌측 상단 파란색 리프레쉬 버튼을 눌으면 칠 아웃믹스 모델이 있다. 그걸 클릭해서 설정하고 실행창의 기능은 아래에서 설명하겠다. 2번과 3번 프롬프트는 자유롭게 입력해도 되지만, 아래 샘플 프롬프트를 참고하면 된다. 그리고 아래 이미지 4번 샘플러 이미지는 DPM++ SDE Kerras로 설정해 준다.
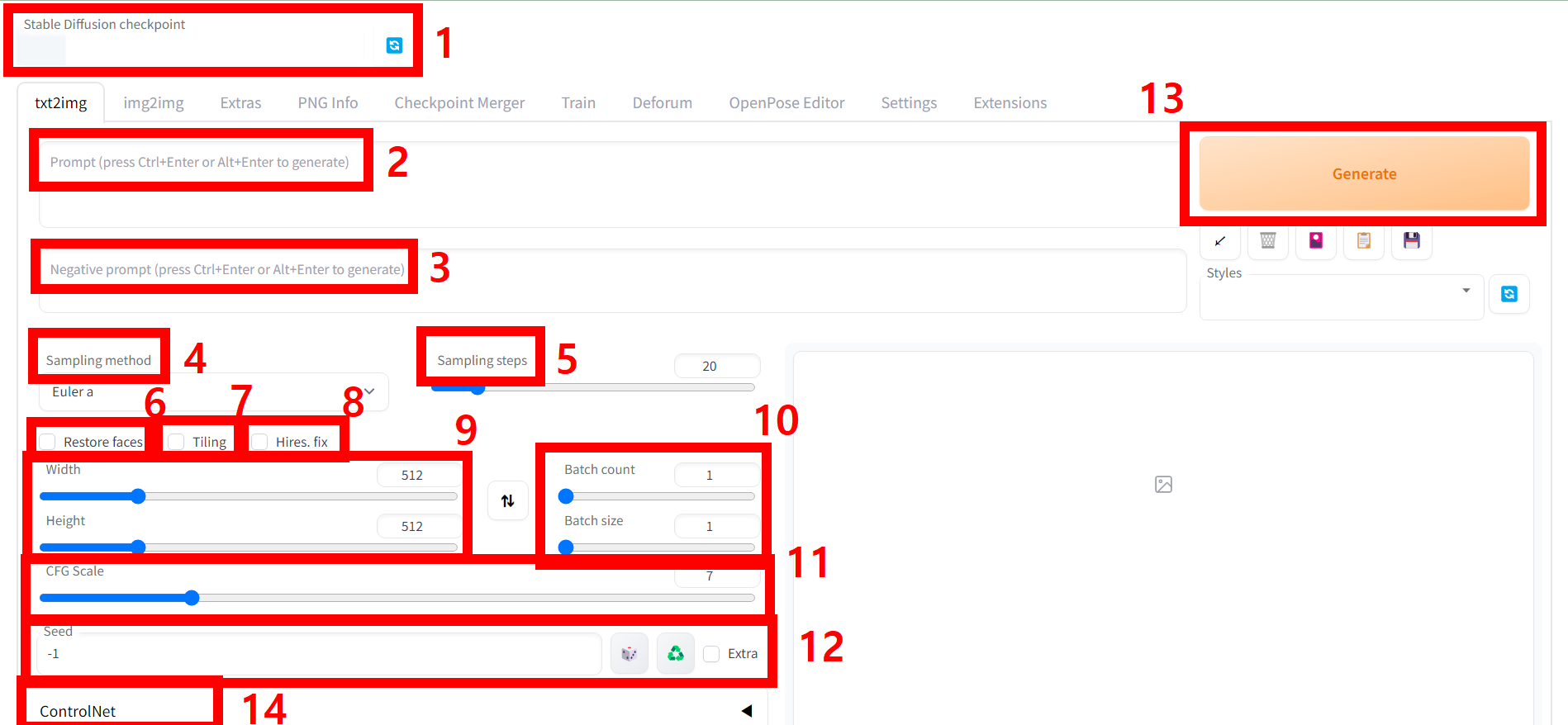
< 각 기능 별 설명 >
1. Checkpoint 설정 : 기본값은 model.ckpt로 되어있으며, 설정 직후 우측 리프레쉬를 눌러 원하는 모델을 설정할 수 있다. 샘플을 만들기 위해 chilloutmix를 선택한다.
2. 프롬프트 창 : 보통 파지티브 프롬프트라고 하며, 원하는 명령어를 입력하는 창이다. 단순히 girl이라고만 해도 출력이 되나, 원하는 모델을 만들기 위해서는 프롬프트를 입력해야 하며, 같은 프롬프트라 해도 다른 결괏값을 출력한다. 원하는 이미지를 얻기 위해 계속 제너레이트 해야 한다.
3. 네거티브 프롬프트 창 : 원치 않은 이미지 생성을 방지하기 위해 프롬프트를 입력하는 곳이며, 기괴한 모습이나, 선정적인 모습 등을 출력을 방지한다.
4. 샘플링 메서드(Sample method) : 어떻게 모델링할 것인지인데 직접 적용해 보면서 적합한 메서드를 찾아야 한다. 보통 euler a, DPM++ SDE Kerras를 많이 쓰며, 예제에서는 DPM++ SDE Kerras 쓸 것이다.
5. 샘플링 단계(Sampling step) : 이미지를 몇 번 개선할 것인가 인데. 보통 20에서 30을 한다.
6. 얼굴보정(Restore faces) : 얼굴 보정, 얼굴이 일그러질 때가 있다. 그러면 설정하자.
7. 타일링(Tillng) : 타일 패턴의 그림인데 별로 사용하지 않는다.
8. 하이어(Hires) : 고해상도 그림 보정이다. 하이어를 클릭하면 아래와 같은 기능이 생성된다.
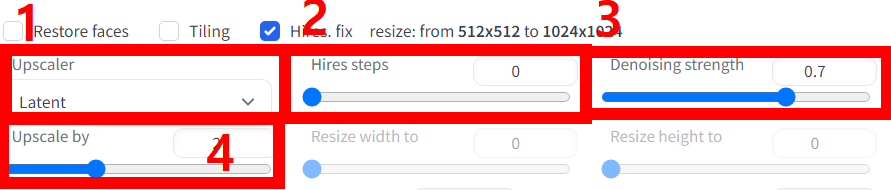
8-1 업스케일러(Upscaler) : 어떤 방식으로 업스케일 시킬 건지 업스케일 모델 설정
8-2 하이어스텝(Hires steps) : 보정할 횟수
8-3 디노이징 스트렝스(Denoising strenght) : 이미지를 기반으로 또 다른 이미지를 생성할 때 기존 이미지와의 유사도를 의미한다. 높을수록 기존 그림과 다르고, 낮을수록 유사하다고 생각하시면 된다.
8-4 업스케일 바이(Upscale by) : 몇 배 업케일 할지. 값을 2로 하면 500X500 그림이 1000X1000이 된다.
9. 크기(Size) : Width는 너비, height는 높이로 사진의 크기를 말한다.
10. 배치(batch) : 배치 카운터는 생성할 이미지의 개수, 배치 사이즈는 한 이미지에 들어갈 이미지 배치 사이즈를 2개 하면, 두 개의 이미지가 하나에 이미지에 들어간다.
11. CFG Scale : 수치가 높으면, 프롬프트의 영향력으로 높으면 의존적이고, 낮으면 자유도가 높아집니다. 보통 7~9 정도로 설정합니다.
12. 시드(Seed) : 시드는 이미지 저장이라고 생각하시면 됩니다. 기본값은 –1인데 이 값으로 두면 저장되지 않고,
다른 값을 지정한 뒤에 불러와서 재 보정 할 수 있습니다.
13. 제너레이트(Generate) : 생성 기능이다.
14. 컨트롤넷(Control net) : 모델 행동 등을 설정할 수 있다. 추후 설명하겠다.
모든 기능이 딱 정해진 답은 없고, 생성과 피드백을 통해 설정값을 바꿔야 한다. 같은 설정값이라도 다른 이미지를 출력하니 경우의 수는 무한하다.
< 샘플 프롬프트 > * 아래 프롬프트 복사를 원할 경우 링크 클릭
- 파지티브 프롬프트(위칸)
<lora:koreanDollLikeness_v15:0.5>, ultra detailed, highres, (realistic, photo-realistic:1.4), 8k, raw photo, (masterpiece), (best quality), physically-based rendering, Female college student, long brown hair, Korea, street, looking, jeans, white T-shirt, realistic photography, professional color graded, 8K, F2.4, 35mm.
- 네거티브 프롬프트(아래칸)
ng_deepnegative_v1_75t, paintings, sketches, (low quality:2), (normal quality:2), (worst quality:2), lowres,((monochrome)), ((grayscale)), acnes, skin spots, age spot, skin blemishes, bad feet, ((wrong feet)), (wrong shoes), bad hands, distorted, blurry, missing fingers, multiple feet, bad knees, extra fingers
위와 같이 설정을 한 뒤에 제너레이트 하면 아래와 같은 이미지가 나온다. 물론 모델 이미지는 조금씩 다르다. 여기까지 진행했으면, 이제 약간의 공부를 통해 어떤 모델도 생성할 수 있다. 다음에는 모델의 움직임과 동영상 등 만드는 방법을 알아보겠다. 제 채널에 활용 영상이 있으니 참고하면 된다. 위 기능에 대한 설명이 부정확할 수 있으니, 피드백 사항이 있을 시 댓글 부탁한다.



스테이블 디퓨전을 통해 아래와 같은 영상도 제작할 수 있으니 많은 관심 부탁한다.
< 아래 링크는 Step by Step 스테이블디퓨전 입문 커리큘럼입니다! >
(전자책, VOD, 전용 오픈채팅방, 실시간 미팅, 과제 등 한 달 커리큘럼입니다!)
'빠르게 배우고 싶다면 클릭하세요!'
'스테이블 디퓨전' 카테고리의 다른 글
| 스테이블 디퓨전 시작부터 룩북 제작까지 (2) | 2023.03.30 |
|---|---|
| 틱톡에 자주 나오는 AI댄스 영상 만들기(미완) (2) | 2023.03.17 |
| 스테이블 디퓨전 확장기능(extensions) ddetailer 등 설치하는 방법! (4) | 2023.03.17 |
| No interface is running right now 스테이블 디퓨전 접속 오류 (0) | 2023.03.15 |
| 스테이블 디퓨전(stable diffusion) 컨트롤넷(Control net) 오픈포즈(openpose)모델로 AI아바타 행동 설정하기! (4) | 2023.03.15 |




댓글